A grimoire of how LLVM translates atomicrmw to x86_64 assembly. Introduction I’ve been working on an LLVM-IR-to-x86_64-assembly compiler recently.
One of the instructions my compiler translates is the atomicrmw
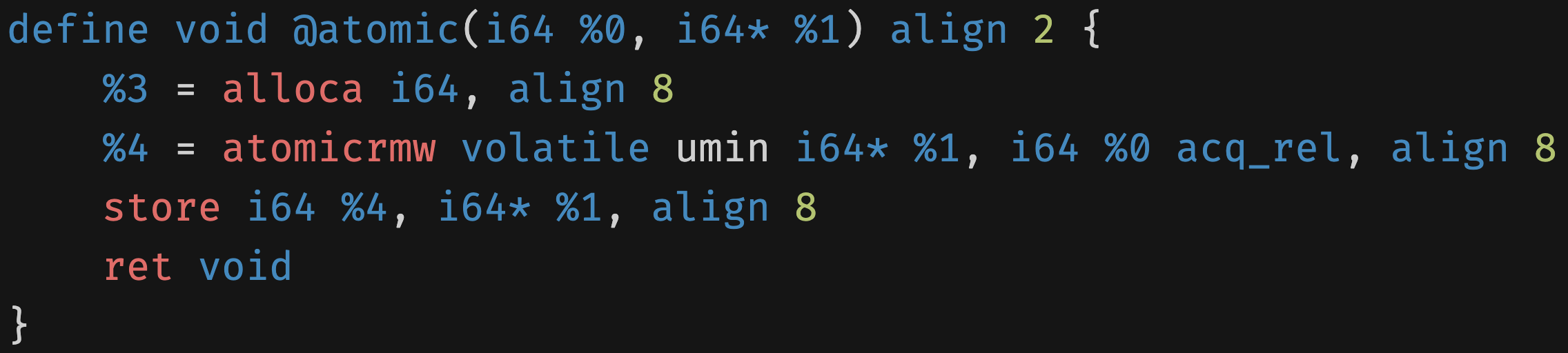
Full IR example 1
2
3
4
5
6
define void @atomic(i64 %0, i64 * %1) align 2 {
%3 = alloca i64 , align 8
%4 = atomicrmw volatile umin i64 * %1, i64 %0 acq_rel , align 8
store i64 %4, i64 * %1, align 8
ret void
}
The xchg operation 1
%3 = atomicrmw volatile xchg i64 * %2, i64 %0 acq_rel , align 8
1
2
# Used or unused result
xchgq %rdi, (%rsi)
The add operation 1
%3 = atomicrmw volatile add i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
# Used result
lock xaddq %rdi, -8 (%rsp)
# Unused result
lock addq %rdi, -8 (%rsp)
The sub operation 1
%3 = atomicrmw volatile sub i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
# Used result
negq %rax
lock xaddq %rax, (%rsi)
# Unused result
negq %rax
lock addq %rax, (%rsi)
The and operation 1
%3 = atomicrmw volatile and i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
8
9
# Used result
movq %rax, %rcx
andq %rdi, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
# Unused result
lock andq %rdi, -8 (%rsp)
The nand operation 1
%3 = atomicrmw volatile nand i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
# Used or unused result
movq %rax, %rcx
andq %rdi, %rcx
notq %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
The or operation 1
%3 = atomicrmw volatile or i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
8
9
# Used result
movq %rax, %rcx
orq %rdi, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
# Unused result
lock orq %rdi, (%rsi)
The xor operation 1
%3 = atomicrmw volatile xor i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
8
9
# Used result
movq %rax, %rcx
xorq %rdi, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
# Unused result
lock xorq %rdi, (%rsi)
The max operation 1
%3 = atomicrmw volatile max i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
# Used or unused result
cmpq %rdi, %rax
movq %rdi, %rcx
cmovgq %rax, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
The min operation 1
%3 = atomicrmw volatile min i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
# Used or unused result
cmpq %rdi, %rax
movq %rdi, %rcx
cmovleq %rax, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
The umax operation 1
%3 = atomicrmw volatile umax i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
# Used or unused result
cmpq %rdi, %rax
movq %rdi, %rcx
cmovaq %rax, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
The umin operation 1
%3 = atomicrmw volatile umin i64 * %2, i64 %0 acq_rel , align 8
1
2
3
4
5
6
7
# Used or unused result
cmpq %rdi, %rax
movq %rdi, %rcx
cmovbeq %rax, %rcx
lock cmpxchgq %rcx, (%rsi)
jne .LBB0_1
Licensed under CC BY-SA 4.0